Triage stream-adventure issue queue
stream-adventure is one of the first workshopper node modules which teaches Streams in node.js. Working on the challenges myself, I got frustrated when simple things did not work for me, so I ended up on the github repository doing a bit of triage during my free time.
The project: why & how
The Why: stream-adventure is a popular project among developers who want to learn node.js and its Streams API which is fundamental. The “workshopper” provides simple and doable steps for learning the subject matter in a practical way . Also, the project is pointed as a historic milestone of nodeschool. Accodring to me, it’s good value: learning node.js while contributing back to a big-impact project.
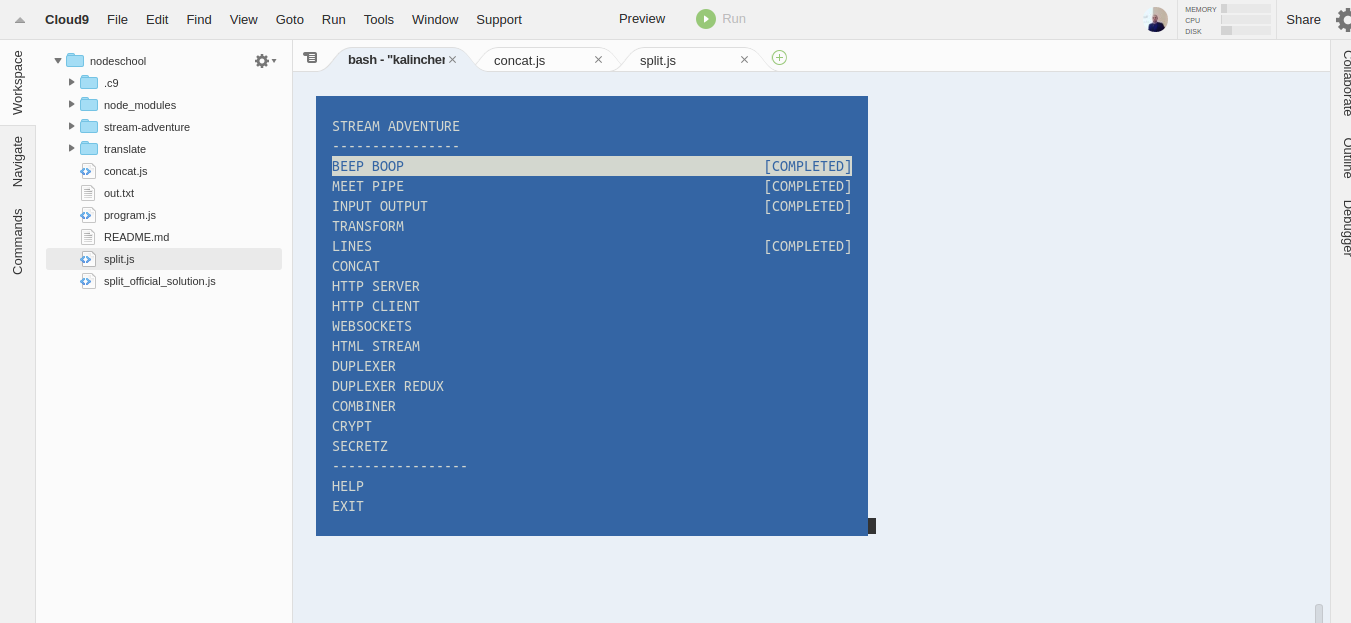
How: installing the project is the same as any other node module. You can do that either locally (when having node+npm) or by using a cloud service like Cloud 9 IDE. I use C9 as it’s convenient to work on the challenges any time and anywhere, in the browser, and the environment has nvm, which makes it easy for me to switch between node versions in case I need to test something special. That’s how it looks — not so bad ;)
By the way, I recently got feedback similar to this one about a requirement of a credit card during registration in C9. Remember that the choice of tools is always up to a personal preferences, i.e. feel free to choose whatever works best for you.
To possible program commands, run stream-adventure help. Most of the time, you’ll need only stream-adventure, stream-adventure print and stream-adventure verify program.js where the program.js is the file containing your solution of the given challenge.
Reporting issues
Reporting issues is really good! Only one suggestion: search the issue queue and or the list of pull requests to check if the issue you’re experiencing is not already reported or worked upon.
Naturally, if the issue is already reported or worked upon, try to support the people working on it in order to speed up the process of solving the issue.
Working on the issue queue
As I wanted to work on the queue for my own benefit of figuring out what is what, etc. initially, I started working in one way and changed my approach on the way. The goal was simple: organize issues and pull request in an effective way for a maintainer to quickly and easily take yes/no decision on solving a given problem.
Strategy 1: Prioritize pull requests
Since I am a “newbie” in both the subject of matter (the streams) and in the project, my first idea was to go through the list of pull requests and categorize them in a way that indicates the readiness to be merged. This way, I imagine, the pull requests being validated and tested can be quickly skimmed and hopefully merged.
This strategy didn’t work very effective for me, since the process was not linear, i.e. frequently I open 1 pull request which solves 1 issue, and then from this issue, I tend to find related or duplicates, and what if there are other pull requests that solve the same issue in another way?
I think that strategy could be effective if the project has a roadmap or a well-defined list of important bugs/features to be handled in a given sprint or milestone.
Strategy 2: Work-out “low-hanging fruits”
This strategy seemed a natural reflex for quick gratification after the first strategy didn’t work quite well :) The idea is simple: go through issues and find such that are either already solved, duplicates, general questions that are already answered successfully, old issues that are not valid any more, etc. These are quick-wins that give a good feeling similar to the one that you experience when you cross an item from the todo list.
I think that this strategy could be the starting point, rather than a bounce-back reflex as I did. The process of sorting easy or already done issues is a low-barrier entrance into the issue queue. And it naturally leads to the need of reading/searching other related issues which is something that has to be done at any case.
Strategy 3: Categorize issues by topic
This small and probably super-obvious step was actually more gratifying than the low-handing fruits. At this stage, I decided that the process of triage the issue queue will be a complementary activity to my own learning path of the module. So, I made a list of the issues, categorized by the topic of the workshopper, i.e. “concat”, “http_server”, “http_client”, etc. and then sorted them in the same way as I would go through them in the workshopper. This way, I reached a natural flow of working on the problem myself trying to solve it (experiencing the same problems as I’d see in the issue queue) and then going through the list of related issues and pull requests.
Sure enough, the sole act of first doing the challenge myself and then reading information and reports about the issue gives a very good background and picture on the way I’d approach the issues and the pull requests. Sometimes opening a pull request suggesting an update in the problem definition could be solving many issues coming from misunderstanding the problem or misunderstanding the expected code implementation.
Strategy 4: Prioritize most recent communication
That’s an approach of working out issues in open source projects in software or software modules that one does not necessarily use directly everyday or is not affected/blocked at a current time. I didn’t prioritize latest communication at this triage because the project is not so big and there aren’t so many issues or pull requests. In case the project involves thousand of developers or sub-functionalities that are not easy to see or figure out, but still feels good to contribute back, that strategy could be useful to get into effective flow of solving problems that are important/actual/active at the current moment.
Strategy 5: Follow your own interest
In a similar way of strategy 3, which involved prioritizing issues by topic, I could say that it’s pretty important to work on issues that are genuinely interesting for oneself. This means that, even if the project was bigger and harder to maintain, the passion which someone has about a topic would always win over a non-interested trivial going through the issue queue solving issues that are not really motivation enough to learn from.
Your feedback is valuable
To summarize this meta-article, your feedback on both the repository of the project and my thoughts are very welcome :)
Sharing is caring!